The Changelog
This post is part of a Series on the Lambda Architecture. It was written in collaboration with Boxever and first posted on Medium.
Overview
To avoid building siloed monolithic datastores, one must ensure that the entity changes applied in one datastore are visible to downstream systems. In addition to this, one of the fundamental requirements of the Lambda Architecture is the presence of an append only immutable datastore that acts as a system of record for all changes. This is known as Event Sourcing or simply Stream Processing and we call the append only journal we store these changes in - the changelog.
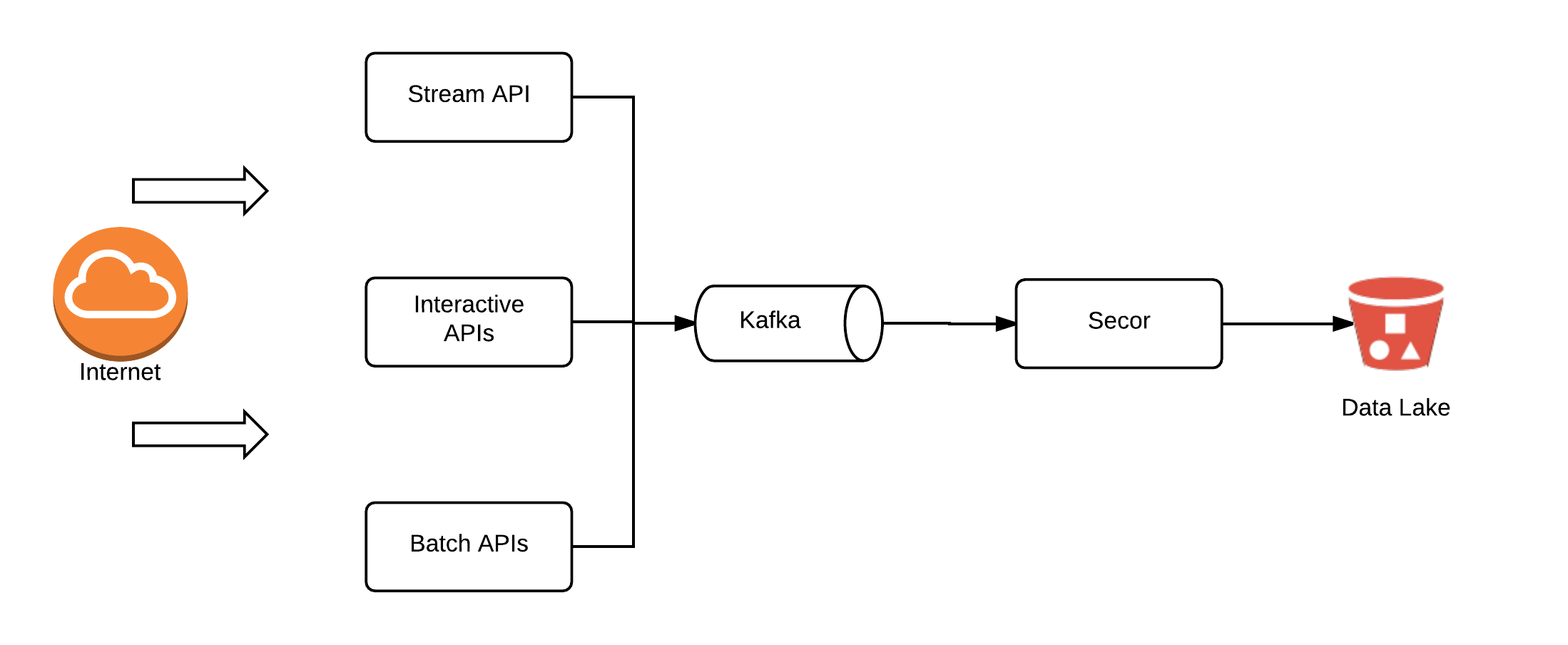
To propagate this changelog around you need a distributed messaging system. We use Kafka as our distributed messaging system. There are many features of the Kafka architecture that make it ideal for Big Data messaging systems but in the simplest terms, it is that it functions as a highly scalable, append only, distributed commit log.
Changelog Architecture
There are no transactions with Kafka which forces one to think in other ways such as idempotency. Idempotency is a mindset and pattern one must embrace in Big Data systems to achieve scale. This doesn’t mean you cannot support exactly one processing semantics and there are excellent frameworks like Apache Flink which provide exactly one processing guarantees when needed. Kafka proposal KIP-98 aims to support transactions in Kafka Streams. Kafka can achieve very high throughput rates for both producers and consumers without issue and you will find most often that the network is the bottleneck (its use of the zero-copy functionality in the JVM is particularly nice and facilitates high throughput).
We have many REST APIs for CRUD operations on transactional and user data. The datastore backing these APIs is Cassandra and we do not have it modeled in an immutable append only manner (even though you could view Cassandras’ data model as an append only commit log if you ignore compactions). However, as we use Kafka for our changelog, we must also publish all CRUD changes we make in our datastores to Kafka. Besides, all of our behavioural data is published straight to Kafka and Kafka only (downstream consumers create views from this).
Publishing the same operation to two datastores from the same process is something which should be avoided. Without distributed transactions (two phase commit), it can and will lead to inconsistencies between the two datastores. Distributed transactions are very difficult to make scale and in general it is better to refactor the architecture to avoid it where possible. Here is an interesting discussion on this topic and various approaches to resolving it via idempotency and eventual consistency. However, unless you have a replayable (hence retryable) datasource upstream, it is not always possible to implement the necessary retry logic.
A much simpler and more powerful approach to the issue of publishing changes to both the datastore which is source of truth and to Kafka (or another messaging system or datastore) is by hooking into the commit log of the primary datastore. This solution has been around for a while with varying levels of support and adoption from different database providers and is more formally known as Change Data Capture (CDC). It has the added benefit of requiring no producer changes, and in fact it is transparent to the producer. The services only write to one location. One particular solution I’ve used in a previous life was Oracle Golden Gate for replicating changes from an Oracle 11G database to an IBM Websphere message queue. There are similar connectors for consuming from various other RDBMS systems (e.g. Mysql, Postgresql) and producing to a variety of datastores including Kafka. Some cloud providers such as AWS support quite sophisticated and seamless solutions using this concept.
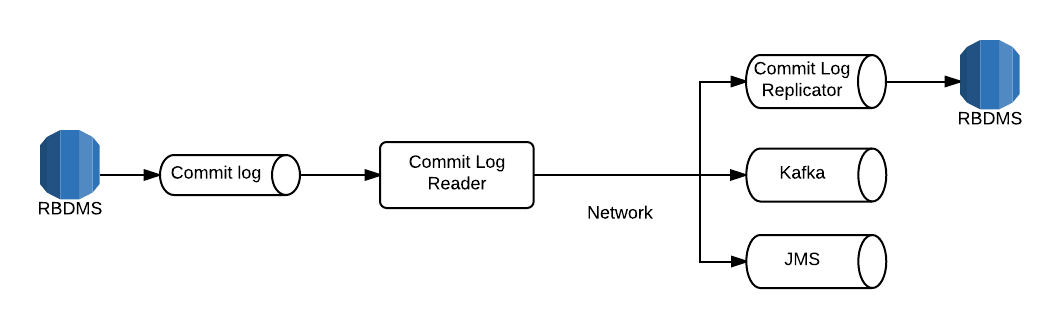
Database Commit Log Replication
It is not possible to achieve this with Cassandra as the Cassandra commitlog does not contain sufficient information. With our CRUD based REST APIs, Cassandra is the source of truth and so we must write to it first and Kafka second. Unfortunately, we did not have the resources to tackle changing our backing datastore for the REST APIs. This means that we have some drift between the changes we write to Cassandra and the changes we publish to Kafka. We track this drift automatically and depending on the issue severity we can decide on a full rebuild of the affected entity type or simply republishing of the entities. While this is not ideal, it is currently sufficient for our use cases.
There are newer and somewhat more experimental approaches to dealing with this issue of read-after-write consistency via APIs and event sourcing. This typically involves something along the lines of Akka and Akka http where all processing is stateful. They can provide a replayable, read-after-write, upstream datasource even for http APIs which means idempotent downstream publishing for http APIs which solves one of the issues we discussed. However, we did not want to have to implement such an architectural change at the time as it was too much risk to change all of our APIs and our data pipeline at the same time. It was a larger change than just changing the backing database as discussed above. Potentially, this can be revisited later but we have some reservations about this type of an event sourcing architecture for all APIs and whether the additional complexity is really worth it vs the database commitlog approach.
Partitioning & Durability
Partitioning and the partition key in Kafka are important concepts. Unlike some messaging systems where one publishes to a queue, in Kafka one can decide on which partition within a topic to publish to. This is how you ensure ordering while achieving scale via partitioning. You should almost always use a consistently hashed partition key instead of random partitioning when producing to Kafka so you can be sure that consumers will read changes for the same entity in-the-order they were applied. It is also important to size the number of partitions correctly as during a partition resize operation, these ordering guarantees are lost unless you implement a stop the world policy during rebalancing which is highly undesirable. See this article by Confluent (the commercial company behind Kafka) on the issue of choosing the number of partitions.
Kafka is a durable datastore (messages are always committed to disk) and is HA (the commit log is replicated across 3 nodes in our setup). However, we do not keep the commit logs forever and have a TTL configured on most of our heavy throughput topics of around 3 days. To ensure we always have this data for replays and change history, we replicate the topics to S3 using Secor within the hour for long term storage. Having the data on S3 enables us to run large batch jobs which consume this data without impacting our primary Kafka cluster which has some real time requirements (we could implement multiple clusters with different throughput and latency requirements but we have not done so yet).
Note that you may find that the Secor logs on S3 are very fragmented depending on how you configure the replication (frequency of uploads, max file size, bucketing etc). A simple solution to this fragmentation is to use S3DistCp which enables you to effectively compact files.
Data Model of Changelog Messages
The format of the messages we publish to this log are
"provenance": {
“apiVersion”: <>,
“serviceName”: <>,
“identifier”: <>
},
"current": <currentEntityState>, // Order, Session, Guest, Event, etc
<"original">: <originalEntityState> // original Order, Session, Guest, etc
}
<originalEntityState> is the entity state before the change which resulted in the new state being published. This is clearly empty when when a change event is published for a newly created entity but if an entity is updated via any API, it should be present here. Behavioural Event entities are immutable and so they will never be published with an <originalEntityState>, only a <currentEntityState>.
With the current and previous (original) entity states, a consumer can analyse any attribute they wish on the entity to determine if it should take an action based on the change. This allows us to completely decouple any downstream consumer logic from upstream producers.
Some might wonder why we don’t produce the more “classical” representation of a changelog where only the changes are published ( as described here ). This has benefits in terms of size and reduced consumer complexity for consumers who only care about the deltas, e.g. aggregate delta management, attribute change time series etc. However, even in the classical representation you should always pass the current and previous state of the changed attributes even if you don’t pass the entire entity as we do here. The reason for this is obvious when you consider an example like maintenance of an aggregate value by some type of downstream streaming analytics. If there is a mutable value like an Order amount which can be updated via APIs, the only way to maintain for example the total spend of the owner of that order by looking at the changelog alone is to know the true Order amount “delta”. You could complicate your producers and APIs to determine this and publish special messages or you could treat it just like any other attribute change and send the original and current values and let downstream worry about determining the change is current amount - original amount. As we publish the entire original and current entity state, we publish more information than is needed in this use case.
The greatest benefit with the approach we have taken is once again in the flexibility it provides downstream consumers. Not just in terms of simplicity but performance. We have many downstream consumers which maintain “views” in different types of datastores for different purposes. Some might be searchable datastore or an active guest cache. In both cases, if we only published the deltas we would have some challenges ahead of us. Both datastores would require the ability to perform partial updates. However, what is a partial update of a key-value cache? Hence, you end up re-reading the full entity from some datastore which provides you access to it in order to rewrite the full entity as key-value into the cache. That is bad enough in terms of performance, but it is even worse in terms of data races and consistency. The delta message which the consumer is basing their action off of was produced at a certain point in time. There is no guarantee whatsoever that another change possibly to the same attribute on the same entity has not occurred since, and then you enter a data race condition with the query you’re performing to get the entity state. You can mitigate this by providing a datastore where you can query for a certain version of the entity but again that is an unnecessary performance and complexity overhead that can be avoided by simply producing the entities as we do.
Thanks to how we publish the messages, we can easily produce a representation with only the changed attributes with minimal effort. We recently came across the following library which implements the Json Patch protocol and means the changelog can be produced by applying the diff between the current and original entity states using this library and writing the patch to another topic.
Data Provenance
Data provenance is used to provide a historical record about the data and its origins. It is essentially metadata about the source of the data. When you receive data from many sources it can become difficult to trace which source the data came from when looking at it in some datastore much further downstream. This can become even more complicated when you have more than one source for the same data where one can update the other. Again, if you are looking at the current state in some datastore downstream there are some key questions you might want to know about the origins of the data. These might include which API, Service or Provider did this come from. Is it composed of more than one and what was the data passed from each that resulted in the current state. This information can also prove to be invaluable for debugging, audit trails and security purposes.
Providing provenance information along with an event sourcing based architecture means that you can always track down and answer these questions.
In our architecture we also have another use for provenance which is to allow us to treat the same data received from different sources differently downstream. For instance, we may not process batch oriented data in the same way as we process real time data and decide to either throttle or filter out completely this data from a given view. Having the provenance metadata on each message makes such an approach trivial.
Next in the series - Batch Serving Views