Why Separate Storage and Query Engine Concerns?
This post is part of a series on Modern Data Warehouse Architectures and was written in collaboration with Oscar Cassetti.
Series Overview
- Modern Data Warehouses
- Design Considerations I - Storage
- Design Considerations II - Interactive & Real-time
- Design Considerations III - Query Engine
Overview
Over the last number of years, there has been a clear trend in the separation of the storage and query layers for data warehouse architectures by web scale organisations. While there have been many driving factors, the progress and penetration of cloud providers has greatly facilitated the adoption of such architectures by increasing the availability to cheap on-demand compute resources, providing essentially infinite scale storage solutions such as AWS S3 and Google Cloud Storage and lightning fast internal network speeds. The business drivers for such an architectural change arise from the continuing need to increase the flexibility of analytics solutions, reduce data model fragmentation which in turn reduces expensive and error prone ETL stages, and at the same time reduce operational overhead and costs.
For years, there was only ever a single analytics data warehouse (OLAP) solution in organisations. This was fraught with issues when it came to web scale companies and is discussed in great detail in this O’Reilly article - “In Search Of Database Nirvana”. While many organisations have adopted a more modern approach to managing data, there is still typically a single centralised OLAP system which is far too slow and expensive when it comes to adapting to new use cases. Similarly, we don’t want to have to create a new Data Mart for every end user and use case we deliver. While there is no such thing as one size fits all in the world of big data analytics, there are architectures which can greatly help reduce the burden of providing and running analytic solutions at scale. At the same time, such architectures can provide the flexibility to use the right tool for the job, without an expensive multi-year project to simply change your query engine or add an additional analytics capability.
The NoSQL trend which spiraled out of control and dominated both OLAP and OLTP for a number of years has died down and while many NoSQL solutions are still ideally suited to certain use cases, they are not being treated as the jack of all trades anymore. Similar to previous generation systems, most (if not all) of these solutions relied on custom storage formats. While these formats helped them meet certain goals, they were often extremely difficult to work with and required managing many database systems with their own storage and operational overhead. The ETL and operational overhead of keeping all of these databases in sync became a tortuous experience for everyone involved. The trend has now turned to providing many different query engines on top of a single storage format, thereby solving the one size fits all problem of the end users but unifying on a suitable storage solution for these disparate tools.
The return of ANSI SQL compatible query engines is extremely pleasing to witness and allows users to once again start unifying analytics capabilities across solutions without product or vendor lock in. We distinguish ANSI SQL compatible query engines such as Presto, Impala, etc from the NewSQL solutions such as MemSQL, VoltDB, Spanner, etc which require caution. As we will discuss later on, some of the NewSQL solutions are attempting to fulfill the one-fits-all systems which tend to end badly. That said, while researching for this blog series, we discovered some very interesting changes being introduced into Google Spanner later this year (see the blog entry and the corresponding SIGMOID ‘17 publication). We feel this deserves its own discussion based on the views we put forward in this series. Therefore, we will review Spanner separately at the end of the series.
There are many decisions that one must make when introducing this new type of architecture and there are already many implementations to choose from. In this post we provide an argument for choosing such a data warehouse architecture, along with an overview of some of the driving factors and decisions which need to be made along the way. In subsequent blog posts we will delve into more technical details on many of these decisions and how to design data pipelines to deliver such a solution.
Why Separate Storage and Execution?
Historically, both storage and execution (query) layers have been tightly coupled into a single database system such as Oracle, DB2, Vertica, MySQL, etc. Each has their own storage format for myriad reasons from vendor lock in, to specific query engine optimisations to simply no need or desire to standardise. Many of these tools did not, and still do not support many of the concepts we take for granted when dealing with big data. That is the ability to scale out horizontally. Queries should be answerable by distributing the data and the workload across many commodity machines. This distribution of the data and query across a cluster is generally known as MPP (Massively Parallel Processing) in the database world. Vertica is an example of an MPP solution which has been around for some time. Database Warehouse Appliances (DWA) were commonly required for such MPP solutions and the specialised DWA hardware required to run it at extortionate prices.
A classical data warehouse architecture tends to look as follows.
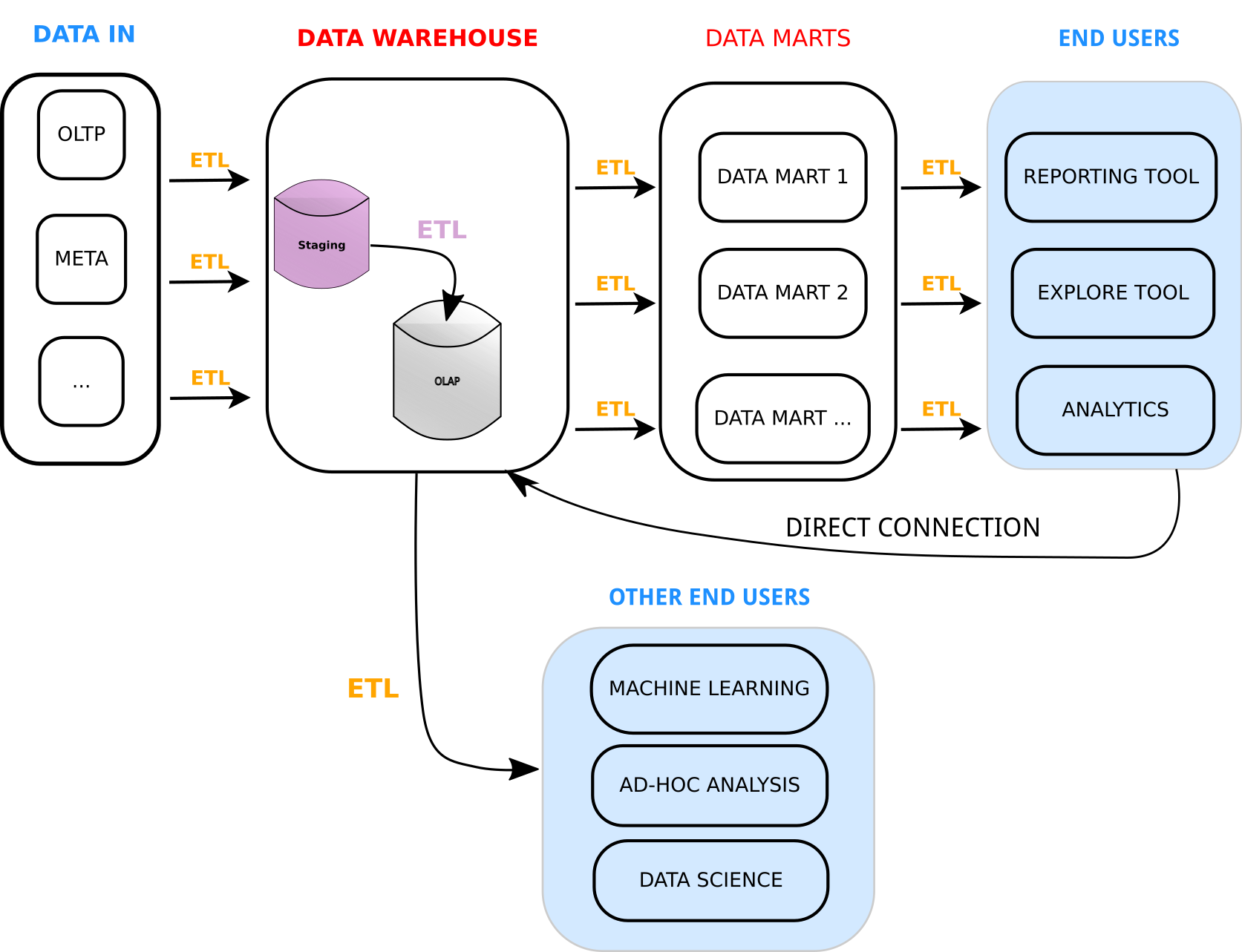
Classical Data Warehouse Architecture
The data in these solutions was always co-located with the engine. Traditional databases, even when running on distributed filesystems such as NFS, create narrow interfaces, where the only way to get at the data is through the database interface. However, very often people need to access the data in different ways and it is difficult for a single solution to specialise for each. This meant that the use cases which could be built from this data were very limited and often painful to create. When web scale companies started appearing, these problems were amplified by orders of magnitude. Even with solving the data capture scaling issues, the solutions that existed simply did not allow access to and use of the data they had captured in an efficient and cost effective manner. This is around the time Hadoop and map-reduce started to appear. It allowed to distribute and run any kind of algorithm (execution) against the data stored a variety of formats in HDFS.
In many ways, MPP and Hadoop are similar concepts. There is a lot of fuzziness in various articles when it comes to describing what MPP is and how it is different to Hadoop or SQL on hadoop solutions. A key difference is that sharing the data is optional in Hadoop whereas in classical MPP it was not. Classical MPP implies a strict shared nothing architecture. When taken in this context, the data isolation adds an upper bound to the cluster concurrency which is limited by the vertical scale of the individual nodes, not the size of the cluster. There are some other differences around pipelined vs staged execution and managing slow nodes (speculative execution) which you can read about in this article. It is clear that we can implement strict MPP on top of modern Hadoop which means we can view MPP functionality as a subset of Hadoop. However, many modern systems take advantage of the benefits of both concepts to provide pipelined, highly concurrent and resilient systems.
Hadoop has no doubt been the biggest player in the Big Data ecosystem over the last 6 years. It was based on a paper by Google which described the map-reduce architecture they had been using for half a decade. It was designed to distribute processing on commodity hardware instead of expensive custom hardware that many of the existing MPP solutions required. At the beginning, data locality was a very important feature in the Hadoop architecture and so the architecture naturally had a strong focus on collocating the execution with the storage. Even though this co-location was an original design decision, Hadoop marked the beginning of separating the execution layer from the data layer. As more and more execution frameworks were written to run on top of YARN, the conceptual separation grew larger and larger. Combined with the ability to read data over the network as fast as, and in some setups faster than from a local disk, the importance of data locality started to fade. While locality is still critical for many applications and use cases such OLTP systems, when a given problem requires the reading and processing of MBs, GBs or TBs of data, the relevance of locality diminishes so long as the network bandwidth is sufficient.
The improvements in storage have largely been driven by faster, cheaper SSD storage and super fast networking combined with the extreme commoditization of storage by cloud providers such as AWS, Google and Microsoft. When operating within these providers data centers, the bandwidth of the network card is typically the limiting factor for read operations from the cloud storage to a compute node within the same network. This means that node level data locality isn’t so important anymore, while data center and region level is still important. This locality indifference is extremely important, because if you must co-locate a query with the data, then there is a direct vertical scaling limit imposed on the operations on this copy of the data. In these situations, avoiding contention and starvation issues become more and more challenging.
The Evolution of the Data Lake
Most organisations have embraced the concept of the “Data Lake”. However, the term “Data Lake” is a poorly defined concept. Does it simply mean a storage medium, where all an organization’s raw data is available, transactional, behavioural and meta? Are there any constraints on the usability and format of this data for it to be classified as a Data Lake? This lack of clarity has in many ways caused a lot of pain for organisations trying to develop Big Data strategies. They put a lot of time and money into building a Data Lake without a clear strategy for how to use it to derive valuable business insight. Most of the time, the ability to deliver this insight is treated as an afterthought, and a more classic data mart and ETL process is still used for analytics and reporting purposes. This had left many organisations who have embraced the concept of a Data Lake with the following data warehousing architecture.
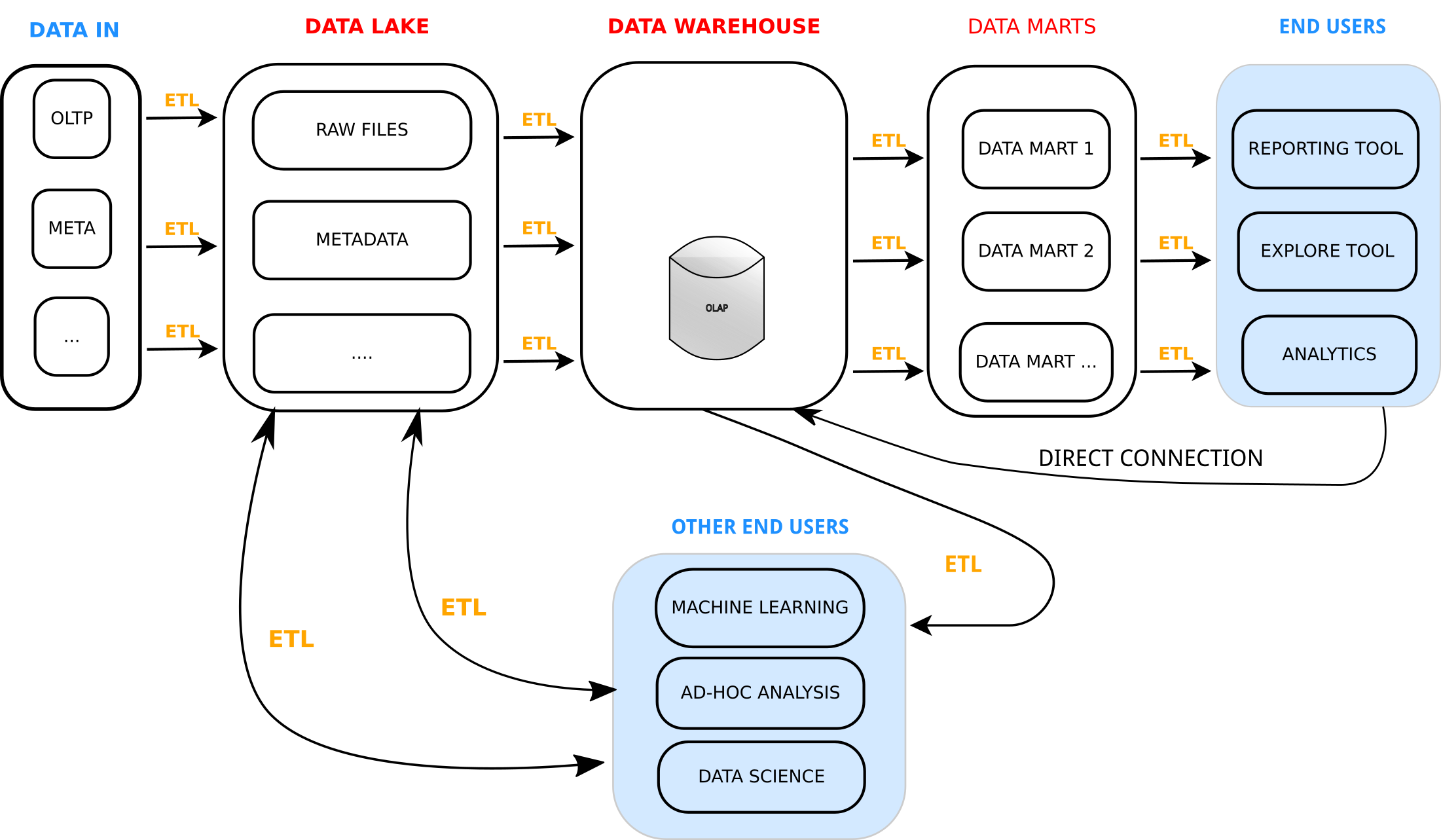
Recent Data Warehouse Architecture
So instead of making life easier, it has actually increased the complexity due to an increased number of ETL steps, each one with its own tools, schemas, headaches and inevitable drift. This data warehousing approach feels very fragmented and overly complex. Of course the data lake brings many benefits. It contains all the data, and so a user working against this data will never be “missing an attribute” that was captured. However, if a newly required attribute is missing from your OLAP, it still requires a potential rebuild or backfill of this attribute to make it accessible historically. Adding a new field requires a cascade of schema changes, migrations and ETL changes.
The increasing importance of AI, machine learning and data science in many organisations means that much deeper and more complete data is required for analysis. Working against existing shallow OLAP systems with their narrow data interfaces just does not cut it. The turn around time for making the required attributes available can be too large and the expense too great. Similarly, a much broader set of execution engines and access patterns are required to facilitate such end users. However, forcing these users to try and work directly against the raw data in the data lake introduces its own issues and delays.
Given all these reasons, the thinking has started shifting towards, “if we have all our data in the Data Lake, how can we make the data lake queryable”. This question is leading to a unification of storage location, schemas and formats for the data lake and an explosion of storage neutral query engines which work directly against it. This concept does not prevent one from keeping all of their raw data in the data lake, even under a separate namespace, it simply begins to merge the data lake and data warehouse storage concepts. This means faster insight cycles and less overhead on data engineering and operations to constantly fix and add new attributes to countless data marts and tables for each new use case. Often, this needless cycle results in use cases becoming too timely and expensive to implement. Such thinking leads to a modern data warehouse architecture such as that shown below.
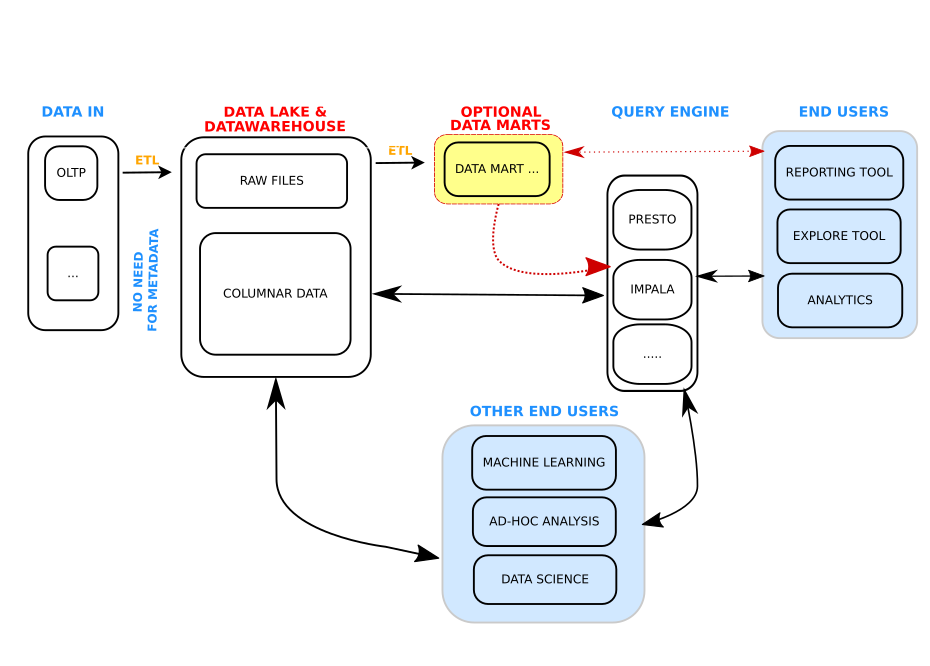
Modern Data Warehouse Architecture
Clearly, there are many benefits to enabling fast, interactive analytics, directly against the data lake. While there are many design decisions and implementation challenges in delivering such a solution, we feel the time is right at least start considering a transition to such a data architecture. Over the next few months, we will bring you through many problems and solutions available to solving these design decisions.
Next in the series - Design Considerations I - Storage